Curso avanzado de ML-Agents de UNITY.
Creamos un NPC capaz de perseguir un target en un entorno Variable. Segunda parte.
Recordemos cuál es nuestro objetivo: Usar Ml-Agents para enseñar a un NPC a cumplir misiones, que sean ir a un punto, en un entorno variable. En el ejemplo he usado un personaje de tipo humanoide que tiene que tocar unos monolitos, pero el aprendizaje podría servir para cualquier personaje que tuviera que ir a buscar diferentes elementos. Lo más importante es que el escenario no tiene que ser siempre el mismo y los elementos no tiene que estar situados siempre en el mismo sitio. Nuestro ML-Agent se debe adaptar al escenario cambiante y al cambio de posición de los targets.
Cualquier duda o comentario de la lección no dudeis en dejarla en el foro del curso.
En la primera parte no lo conseguí, fue digamos que un fracaso anunciado. El agente solo conseguía encontrar los targets si estos no variaban de posición, y tampoco es que se llevase muy bien con los cambios de escenario , es decir, no conseguía esquivar las rocas o paredes nuevas que se introducían en el escenario.
Así que este es nuestro punto de partida: TENEMOS UN NPC CAPAZ DE LOCALIZAR TARGETS QUE NO SE MUEVEN EN UN ENTORNO FIJO. Queremos: UN NPC CAPAZ DE LOCALIZAR TARGETS QUE CAMBIAN DE SITIO EN EN ENTORNO VARIABLE.
Modificamos la función CollectObservations
Lo primero era modificar nuestra función CollectObservations, vamos a simplificarla. Si recordáis le pasábamos la dirección y la distancia de todos los targets, junto con un array que indicaba que target era el activo. Ahora tan solo le vamos a pasar la distancia y dirección al target activo, obviando los otros dos.
public override void CollectObservations(VectorSensor sensor1)
{
for (int n = 0; n < _target.Length; n++)
{
if (_target[n].isLigthActive())
{
sensor1.AddObservation(Vector3.Distance(_target[n].transform.position, transform.position));
sensor1.AddObservation((_target[n].transform.position - transform.position).normalized);
}
}
sensor1.AddObservation(
transform.forward);
}
Esta función ahora si que no tiene ningún secreto. De entre todos los targets, buscamos el que tiene la luz activa y es el que usamos para pasar sus datos a las observaciones.
Resumiendo, el motor de Machine Learning recibe:
- Distancia del ML-Agent al target.
- Dirección del ML-Agent al target.
- Vector Forward del ML-Agent.
Pero estas observaciones no son las únicas con las que cuenta nuestro agente, también le he incorporado un componente RayPerceptionSensord3D preparado para detectar los muros, los targets y los bordes.

Pues con la función OncollectObservations modificada llega el momento de realizar un nuevo aprendizaje.
Test 12.
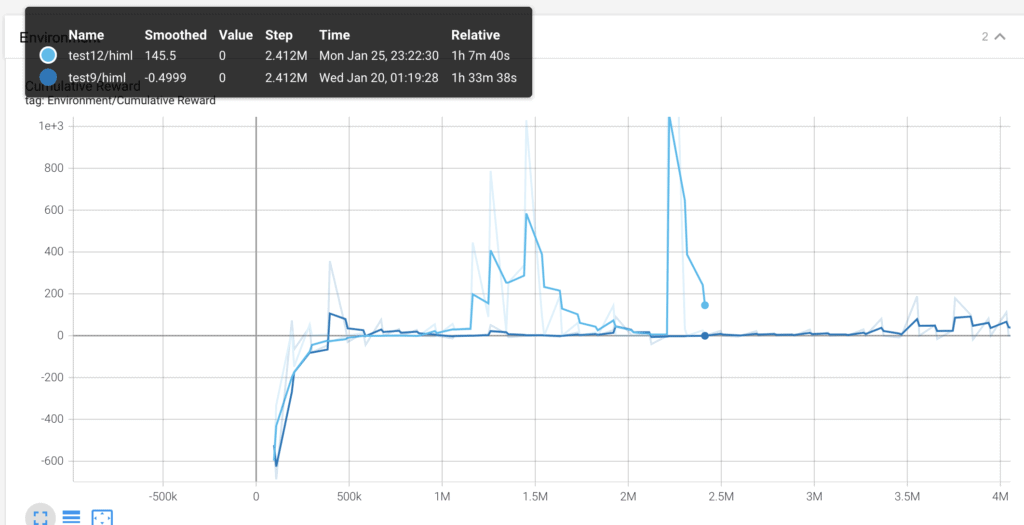
Ha sido un fracaso. Las curvas que estamos viendo es la actual, con la nueva función (azul claro) y la anterior, con la función OncollectObservations sin modificar. He parado el proceso de aprendizaje cuando tan solo llevaba una hora porque estaba claro que la cosa no funcionaba.
La forma tan irregular de la curva me hace pensar que hay un problema con el fichero .yaml. Y después de estar un tiempo estudiando he dado con un error grave. El parámetro batch_size tiene un valor de 3000 en lugar de 300. Tan solo un 0, pero un error que arrastro desde casi el primer aprendizaje. Es un error grave, por que, tal como ya se explica en la lección: la importancia del fichero .yaml, el valor de buffer_size debe ser un múltiplo superior al de batch_size, y no lo era.
Test 13.
He cambiado el batch_size de 3000 a 300. Realizo un nuevo proceso de aprendizaje, con este fichero .yaml.
behaviors:
himl:
trainer_type: ppo
hyperparameters:
batch_size: 300
buffer_size: 37200
learning_rate: 0.0003
beta: 0.001
epsilon: 0.2
lambd: 0.95
num_epoch: 8
learning_rate_schedule: linear
network_settings:
normalize: true
hidden_units: 128
num_layers: 2
vis_encode_type: simple
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0
keep_checkpoints: 5
max_steps: 10000000
time_horizon: 1000
summary_freq: 12000
threaded: true
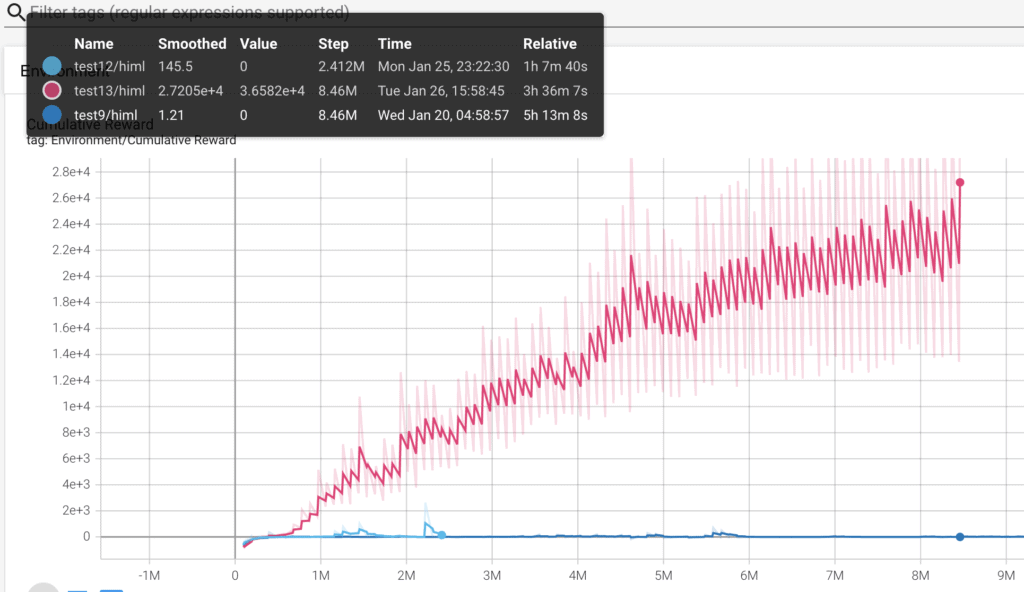
La mejora es realmente impresionante, no hay posibilidad de comparación con las otras dos curvas, y eso tan solo rectificando un error en el fichero .yaml. Claramente hay problemas en el aprendizaje, la curva tiene muchos picos, es muy inestable, parece buena en comparación, pero seguro que todavía hay margen de mejora.

El resultado después de 3 horas de training es bastante bueno, pero se puede mejorar, el ml-agent da algunas vueltas innecesarias y de tanto en tanto se queda atascado contra los muros. Pero bueno, parece que ya se ha conseguido que funcione con los targets cambiando de posición.
Test 14.
Pruebo de modificar el learning_rate_chedule, de linear a constant. En un principio en un entorno variable, como el que queremos llegar es mejor tener el valor a constant.
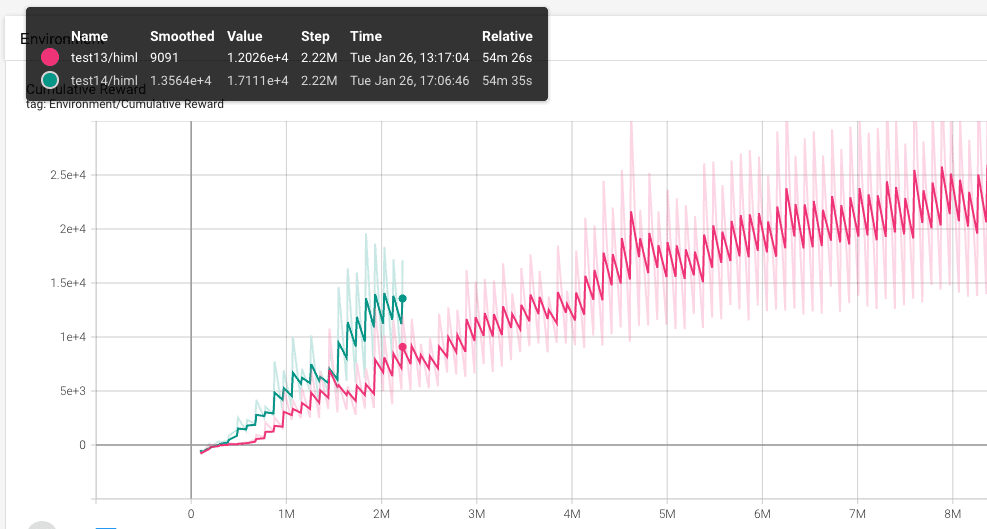
Se puede ver que el resultado es un poco mejor, pero no lo suficiente, por lo que decido para el training antes de la hora. Como muchas de las pruebas las he realizado con el error en el parametro batch_size decido empezar de nuevo. Un buen sitio para buscar ideas frescas e inspiración en cuanto a los ficheros .yaml son los ejemplos de Unity. Voy a probar con ficheros .yaml que han usado ellos a ver como funciona.
Test 15.
Voy a probar con el fichero .yaml del proyecto pyramids. Este proyecto tiene un agente que va circulando entre salas hasta que encuentra un boton y despues se dedica a tirar bloques…. me parecio que el problema a solucionar podía ser parecido al de nuestro ejemplo. Veamos el fichero:
behaviors:
himl:
trainer_type: ppo
hyperparameters:
batch_size: 128
buffer_size: 2048
learning_rate: 0.0003
beta: 0.01
epsilon: 0.2
lambd: 0.95
num_epoch: 3
learning_rate_schedule: linear
network_settings:
normalize: false
hidden_units: 512
num_layers: 2
vis_encode_type: simple
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0
curiosity:
gamma: 0.99
strength: 0.02
encoding_size: 256
learning_rate: 0.0003
keep_checkpoints: 5
max_steps: 10000000
time_horizon: 128
summary_freq: 30000
threaded: true
- Posiblemente las mayores diferencias con el fichero que venía usando hasta ahora es el valor de batch_size y buffer_size, más pequeños en el actual, así como el de hidden_units, que casi multiplica *4 el del fichero -yaml anterior.
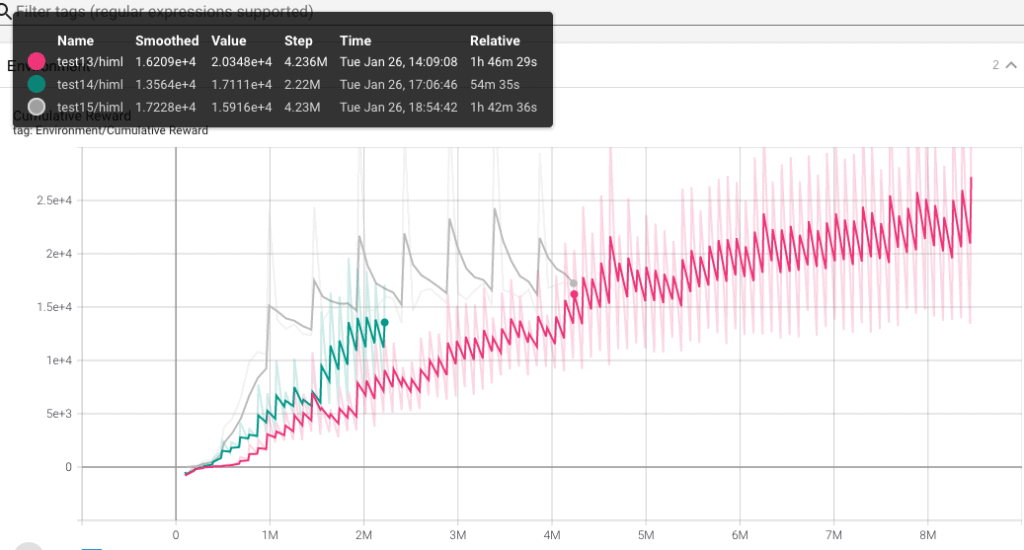
Este nuevo aprendizaje lo vemos en la curva gris…. y no me gusta NADA! En un principio parece muy prometedor, pero a mi es que estas subidas y bajadas no me gustan. Estoy empezando a pensar que son manias mias. Pero igualmente si lo dejo avanzar parece que no mejora a la curva del test13. Así que lo paro antes de que llegue a las dos horas.
Test 17.
Voy a jugar un poco con el fichero .yaml. normalize pasa a true, time_horizon de 128 a 1000, lambd de 0.95 a 0.90 y buffer_size de 2048 a 1024. Claramente son demasiado cambios Pero pensad que ya llevo 17 entrenos, algunos de pocas horas y otros que los he dejado durante toda la noche, así que esto se puede decir que ya es un acto desesperado.
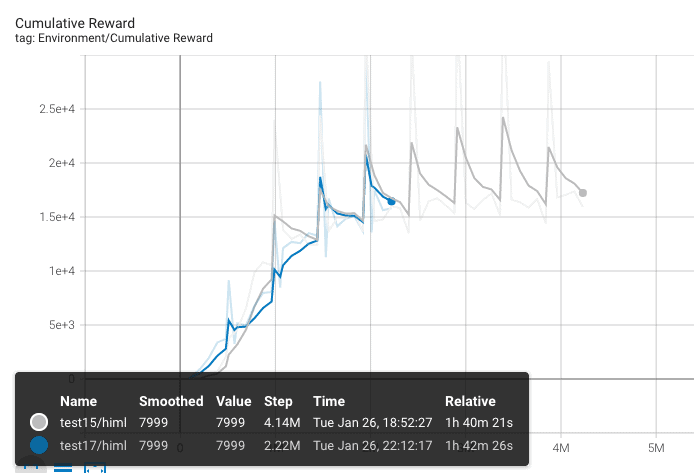
Sorprendentemente después de casi dos horas de training me doy cuenta que la curva con los nuevos valores es calcada a la anterior. ¿Que ha pasado? Posiblemente sea el valor de hidden_units el que esté provocando este comportamiento. Pero decido buscar otro fichero .yaml
Test 19.
Voy a probar con el fichero .yaml de un proyecto llamado GridWorld. En este el agente tiene que llegar a un target esquivando los obstáculos. Pero hay una gran diferencia, su escenario es muy pequeño y simple, mucho más pequeño que el de nuestro ejemplo.

Aquí no hay gráfica, el time_horizon es tan pequeño, que el agente no tenía tiempo a moverse antes de volver a iniciar el entorno.
Test21.
Ahora toca el del proyecto pushblock. el agente debe encontrar un bloque y empujarlo hacia una zona predeterminada. No es tan diferente a lo que voy buscando así que…. voy a probar.
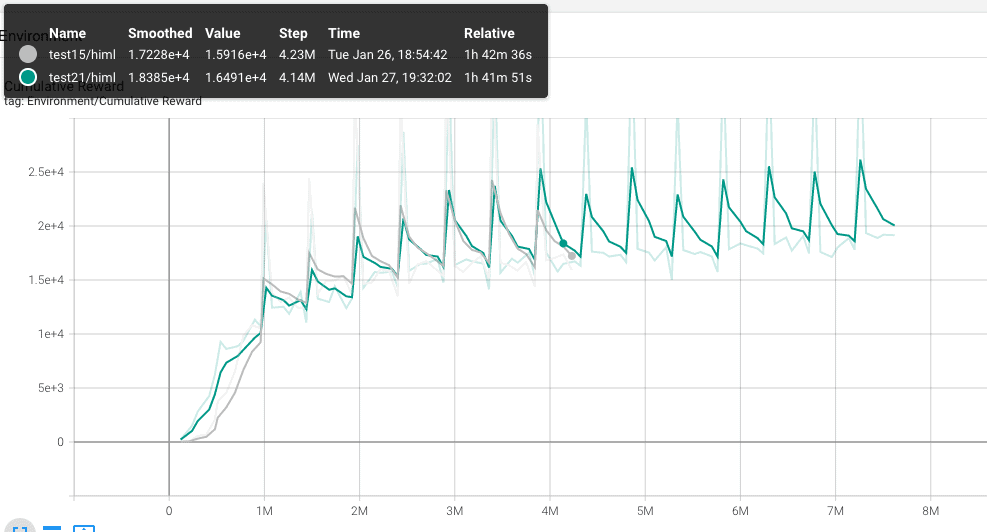
Bueno, pues parece que calcamos el resultado del test15.yaml. Voy a probar otra estrategia, me quedo con este fichero .yaml. Los resultados del agente son más o menos buenos, intentaré mejorar esto con modificaciones en los premios y castigos.
Test 22.
Modificó el script de agente y le doy un pequeño castigo (-1f / MaxStep) por cada paso, así intentó que se vuelva un poco ahorrador. Es decir, que de los mínimos pasos posibles para conseguir el objetivo.
También le doy un castigo (-0.05) mientras esté tocando uno de los muros.
Retoco la configuración de RayPerceptionSensor3d pasando el Stacked Raycast de 1 a 3 y aumentando el número de rayos de 8 a 10.
Incoporo una observación nueva a la función OnCollectObservations: sensor1.AddObservation(transform.InverseTransformDirection(transform.position));
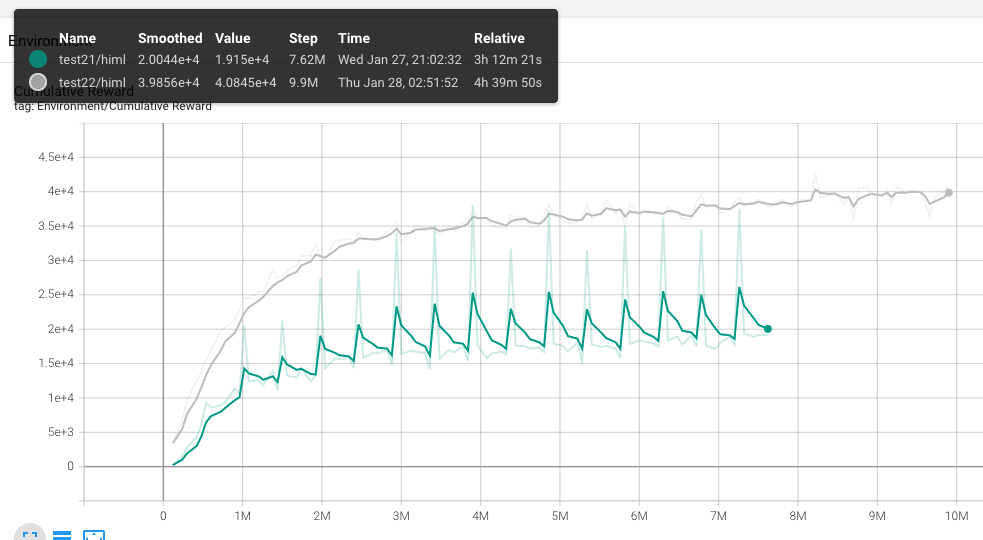
Pues después de estar obsesionado con el fichero .yaml resulta que como mejores resultados he conseguida ha estado modificando los premios y los castigos, así como incorporado una nueva observación. Aunque no se porque, sospecho que esta nueva variable observada no est tan importante como la modificación del componente RayPerceptionSensor3d.
El modelo me parece bastante bueno, vamos a probarlo.
Primera ejecución del test 22.

Para esta ejecución he incorporado dos muros nuevos. Vemos como el ML-Agent funciona bastante bien, encuentra los targets, pero…. de tanto en tanto se queda parado contra un muro. Lógicamente es uno de los nuevos muros, el ML-Agent, aunque lo detecta con el RayPerceptionSensor3d no es capaz de esquivarlo. Nos encontramos con el mismo problema. Si no entrenamos al agente con diferentes muros el s aprende la posición. Es decir el identifica que ir a la posición del muro es algo malo, pero no identifica que sea malo tocar un muro. Por mucho que creemos muros con la misma etiqueta que los anteriores, el no es capaza de saber que no puede cruzarlos, y que recibirá un castigo al tocarlos.
Parece claro que nos toca hacer algún training nuevo,con los muros cambiando de posición.
Test 23.
He modificado la función OnEpisodeBegin para que cambie de posición los muros en cada nuevo episodio. Ya sabéis que cada cierto número de pasos, configurable desde el IDE de Unity en el campo MaxSteep, el entorno se reinicia y el agente empieza de nuevo. Pues bien al cambiar de posición los muros hacemos que no entrene siempre en el mismo escenario.
public override void OnEpisodeBegin()
{
_rb.velocity = Vector3.zero;
_rb.angularVelocity = Vector3.zero;
NewPosition();
_previous = transform.position;
if (walls != null)
{
foreach (GameObject wall in walls)
{
NewPosition(wall.transform, 5f, 0.01f);
}
}
}
Tengo los muros en un Array de gameObjects llamado walls y lo recorro llamando para cada uno de ellos a una función que les busca una nueva posición dentro del escenario.

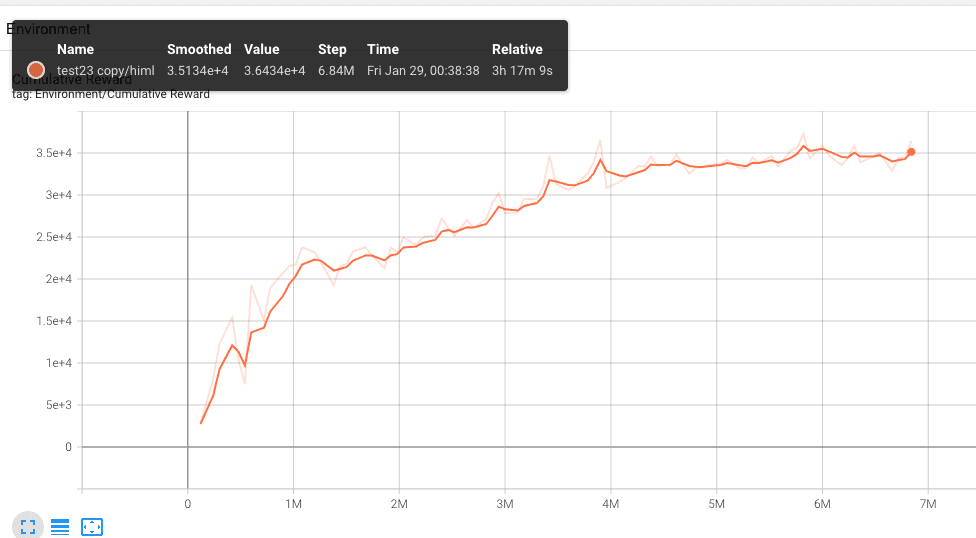
La curva es bastante buena, y el comportamiento del agente también. Después de 4 horas de entreno el agente se mueve de forma correcta y es capaz de localizar los targets estén donde estén los muros! Así que decido poner más muros, pero no quiero perder este entreno… que son 4 horas!!!!
Por lo que usaré la opción –resume del comando de aprendizaje para sumar este nuevo aprendizaje al ya existente.
Test 23b.
mlagents-learn ./trainer24.yaml --run-id Test23 --resume

Como se puede ver, el escenario aumenta un poco la complejidad con cuatro muros, pero el agente consigue esquivarlos correctamente, aunque cambien de posición.
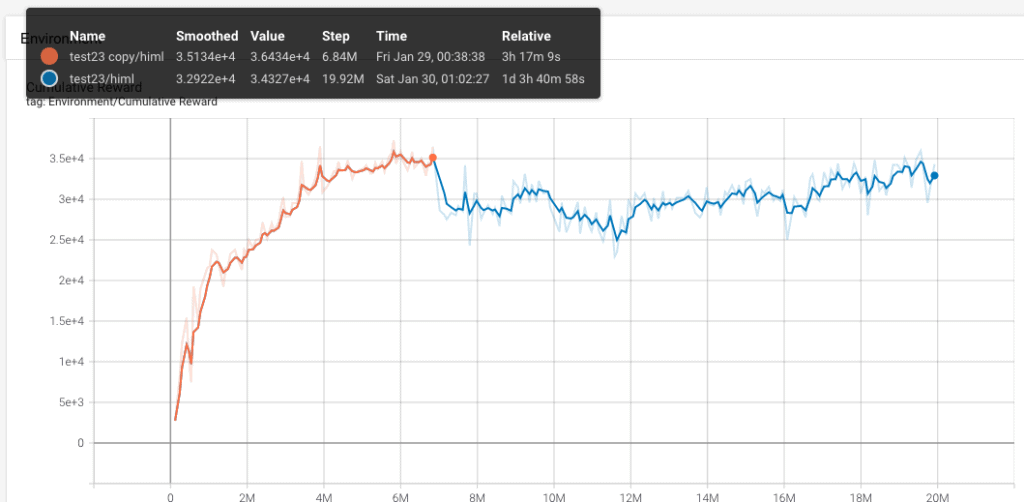
El aprendizaje nuevo es la línea azul, se ha construido a partir del aprendizaje anterior, linea naranja, empieza descendiendo porque la incorporación de dos muros nuevos hace que el escenario sea más complicado, pero al final va aumentando. Estamos ante un aprendizaje, que en total han sido casi 30 horas!!!!!!!
Es una locura! Muchísimo tiempo. Pero el resultado ha valido la pena, por fin tenemos un agente que es capaz de acceder a los targets que cambian de posición en un escenario que no es siempre el mismo!!!!!
Ejecución 1 del Test 23b.

Como vemos en este laberinto nuevo el ML-Agent se mueve perfectamente, quizás no siempre encuentra el camino mas optimo, pero hay que reconocer que encuentra los targets bastante bien y esquiva los muros sin problemas. Esto no significa que vaya a ser capaz de moverse perfectamente en todos los entornos, se lo voy a intentar complicar un poco cambiando los muros de posición.
Ejecución 2 del Test 23b.

Aquí hemos partido el escenario en dos mitades, hay veces que el agente no acaba de encontrar el camino para ir hacia la otra mitad, pero son pocas, y lo acaba solucionando cuando se activa un target nuevo. El comportamiento continúa siendo muy bueno! Pero podemos “hackearlo”, voy a probar con una nueva ejecución diseñando el escenario de tal forma que sea complicado solucionarlo.
Ejecución 3 de Test 23b.
He construido una especie de jaula. Hay un par de salidas, y realmente el ML-Agent al principio del vídeo sale de la pista, pero con la mala suerte que vuelve a entrar persiguiendo el target. A partir de este momento ya no es capaz de encontrar la salida de nuevo. Si os fijais es muy fácil ver porque no la encuentra, la disposición de las paredes no deja que los rayos de RayPerceoption3d detecten la salida de la derecha, que queda oculta por un pequeño muro.
¿Puede solucionarse? Pues claro que si! Todo se puede afinar. Pero por ahora podemos dejarlo aquí.
Resumen de la creación del ML-Agent.
Se puede decir que el objetivo se ha cumplido. El Ml-Agent es capaz de llegar a los targets, pongamos donde pongamos las paredes. El camino ha sido largo, muy largo. Los dos errores principales han sido:
- Mal diseño de la función OnCollectObservations. Aunque ya lo tenía claro. Respondía a una intención mía de ver como el motor de machine learning conseguía relacionar dos variables en un principio independientes.
- Un error al dar valor a uno de los parámetros del fichero .yaml. En una de las pruebas previas he cometido un error al informar batch_size. Posiblemente todos los trainings del 4 al 13 se han visto afectados, y eso son muchas horas. Muchos intentos.
¿La clave? Creo que no se puede decir que existan tan solo una clave, pero si que tenemos un punto que quizás he olvidado al principio y que ha significada una grata sorpresa cuando me he puesto a modificarlo: el reparto de premios y castigos. Es uno de los puntos claves del Machine Learning y al que no suelo darle tanta importancia. Parafraseando a un Monarca: “Me he equivocado, No volverá a pasar”.
El NPC ha sido mejorado usando un pequeño truco con los RayPerceptionSensor3D. Se puede ver en la lección: Usando un segundo RayPerceptionSensor3D para mejorar un NPC, de este mismo curso.