Curso avanzado de ML-Agents de UNITY.
Usando Imitation Learning en un proyecto sencillo
Cualquier duda o comentario de la lección no dudeis en dejarla en el foro del curso.
Imitation learning es una forma de entrenar a nuestros agentes, en la que estos aprende a través de demostraciones. En teoría no serian necesarios premios ni castigos y el agente resultante tiene que tener un comportamiento más parecido al de un jugador, ya que ha aprendido directamente de un humano. Realmente podría ser así en proyectos de Machine Learning, pero con ML Agents, que recordemos es la implementación de Unity. El Imitation Learning se suele usar como refuerzo, o base de un aprendizaje desasistido. Es decir, continuamos entrenando a nuestro agente como siempre, pero una de las entradas es el aprendizaje que hemos creado manejando nosotros el agente.
reward_signals:
gail:
strength: 1.0
gamma: 0.99
encoding_size: 128
demo_path: demos/fichero.demo
El proyecto.
Veamos el proyecto de Unity que tomamos como base para practicar un proceso por imitación con nuestro Ml-Agent: Se trata del típico juego de Pong, pero para un solo jugador. Nuestro agente es la pala, y tiene que aprender a devolver la pelota.
Tenéis disponible el proyecto para descargar en este enlace: mlpong_imitation.
Pero en el fichero tenéis tan solo el proyecto Unity, hay que montar el entorno de Anaconda. Para ello vais a necesitar el fichero .yaml. Veamos el usado:
behaviors:
mlpong:
trainer_type: ppo
hyperparameters:
batch_size: 64 #32
buffer_size: 512 #256000 #256
learning_rate: 0.0003
beta: 0.005
epsilon: 0.2
lambd: 0.90 #0.80 #0.95
num_epoch: 3 #3
learning_rate_schedule: linear
network_settings:
normalize: true #false
hidden_units: 256
num_layers: 2
vis_encode_type: simple
reward_signals:
extrinsic:
gamma: 0.9
strength: 1.0
gail:
strength: 0.05
gamma: 0.90
encoding_size: 64
use_actions: false
demo_path: ./demos/pongrrec.demo
demo_path: ./demos/pong2rec.demo
demo_path: ./demos/pong1rec.demo
keep_checkpoints: 5
max_steps: 1000000
time_horizon: 1000
summary_freq: 5000
threaded: true
Como podéis ver es un fichero .yaml común. Pero tiene un apartado nuevo que corresponde al imitation learnig. Es el apartado gail, que encontramos dentro de reward_signals.
Si necesitáis profundizar en cómo configurar un fichero .yaml tenéis la lección La importancia del fichero .yaml a vuestra disposición. En esta lección tan solo explicaremos el apartado referente al imitation learnig.
Veamos el significado de sus variables:
- strength: Este valor indica por cuanto se debe multiplicar las recompensas que se obtiene teniendo en cuenta la observación extrínseca, es decir, la basada nuestros ficheros Demo. Su valor debe estar entre 1.0 y 0.01. Como más malas sean las muestras que le damos, más bajo tendría que ser el valor. Tenemos que tener en cuenta que si la demostración la ha grabado un humano, sera mala. Así que si le damos cómo entrada ficheros demo que hemos conseguido jugando nosotros tendríamos que poner un valor bajo para tener un mejor aprendizaje.
- gamma: Factor de descuento para los premios futuros. Es decir, cuánto se reduce el peso de los ejemplos en referencia al peso del propio aprendizaje del agente. El valor suele estar entre 0.8 y 0.99.
- encoding_size: El tamaño de la capa oculta que usa el discriminador….. Hablando en plata: Su valor tiene que estar entre 64 y 256. Si lo ponemos muy pequeño le costara aprender del proceso actual, si lo ponemos muy grande el entreno sera muy lento. Hay que probar.
- use_actions: Puede ser true o false. Si lo ponemos a true, usará las acciones de los ficheros demo, si lo ponemos a false, se basara tan solo en sus observaciones, pero decidirá sus propias acciones. A no ser que tengamos unos ficheros demo muy buenos lo mejor es tener este valor a false.
- demo_path: nuestros ficheros de demostración pregrabados. Le podemos indicar tantos como tengamos.
Mucha más información en este enlace del github oficial de los ml-agents: https://github.com/Unity-Technologies/ml-agents/blob/master/docs/Training-Configuration-File.md#behavioral-cloning
¿Cómo creamos los fichero demo?
Increíblemente sencillo. Tenemos que tener nuestro agente para que funcione en modo Heurístico, es decir que pueda ser manejado por el usuario, y añadirle un componente llamado Demonstration Recorder.
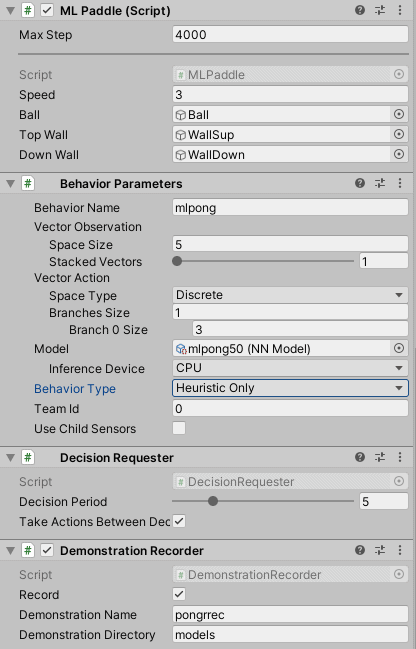
Aquí podemos ver la configuración de nuestro agente. Vemos que le hemos cambiado el Behavior Type en Behavior Parameters para indicarle que use modo Heuristico. Con lo que el control lo realizará el player y no el motor de Machine Learning.
En la parte inferior de la imagen encontramos el componente Demonstration Recorder.
Tiene tres variables que podemos informar y que se describen por su mismo nombre.
- Un checkbox que indica si queremos, o no gravar la ejecución.
- El nombre que le queremos dar al fichero .demo, que contendrá la grabación a usar posteriormente en el fichero .yaml.
- El directorio donde queremos guardar los ficheros. El directorio es relativo al del proyecto de Unity.
¿Realmente se nota la diferencia al usar Imitation Learning?
No hay mejor forma, que mirar las curvas que obtenemos con TensorBoard. Así que veamos la de nuestro ejemplo. Un sencillo programa de Pong, que no tendría que ser uno de los proyectos que más se beneficie de este tipo de entreno. Un proyecto más complejo, donde el agente tuviera que tomar diversas decisiones, dependiendo de acciones previas, sería un candidato más proclive a obtener una mejora importante.
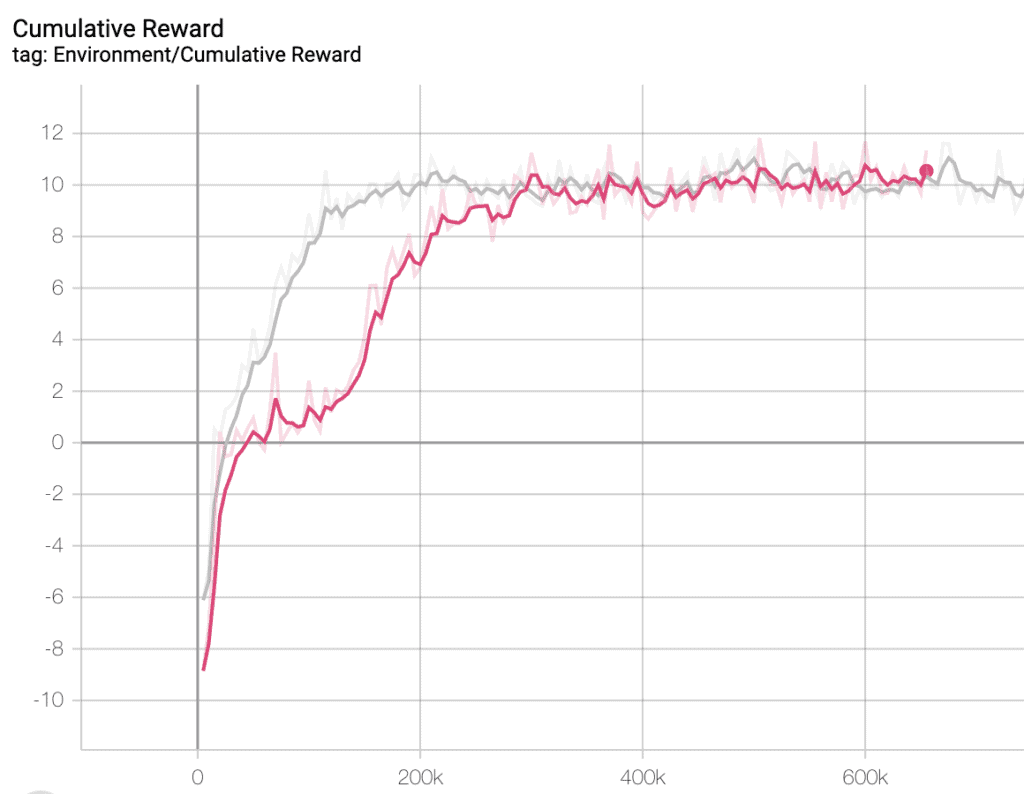
La curva gris corresponde al proceso de aprendizaje que se ha realizado con Imitation Learning, podemos ver que su punto inicial es mejor que el de la curva Rosa y llega antes al punto máximo de aprendizaje.
Las dos curvas llegan al mismo punto, pero una lo hace antes. Se tiene que remarcar que este es un proyecto muy sencillo, en el que nuestro agente, puede aprender enseguida cual es misión. Veremos más adelante cómo el proceso de aprendizaje basado en Imitación puede mejorar la curva de aprendizaje de un proyecto más complejo.