Curso avanzado de ML-Agents de UNITY.
La importancia del fichero .yaml
Si has dado ya tus primeros pasos con ML-agents, seguro que te suena el fichero de configuración .yaml. Bueno, este no es un fichero que sea exclusivo de Unity, se trata de un fichero de configuración del motor de Machine Learning Anaconda, que es el que usa Unity pasa sus Ml-Agents.
Cualquier duda o comentario de la lección no dudeis en dejarla en el foro del curso.
Los parámetros que se configuran en este fichero le indican al motor cómo tiene que tratar la información que va a recibir de las diferentes observaciones y premios que reciba el agente.
La pregunta es: ¿Puede marcar la diferencia el fichero .yaml? Como respuesta obtenemos un claro y rotundo: SI!
Vamos a ver un ejemplo de la importancia de este fichero.
Trabajamos en un proyecto muy sencillo, un pong, y mediante ml-agents entrenamos a la pala que se enfrentará a nuestro Player.
Características principales del proyecto:
- Space type: Discrete. Se podría haber usado un space type continuos, para este proyecto realmente importa poco.
- Vector Observation 5.
- Posición x de la bola.
- Posición y de la bola.
- Velocidad x de la bola.
- Velocidad y de la bola.
- Posición y de la pala. (no se desplaza por X).
- Premios:
- Positivo de 2 al tocar la bola. El refuerzo positivo.
- Negativo de -0.05 al tocar el borde de la pista.
- Negativo de -0.05 si insiste en ir en la misma dirección una vez toca el borde. Con esto penalizamos que se dedique a empujar el borde una vez ya lo ha tocado.
Veamos el script usado, que no es nada mas ni nada menos que la implementación de las características remarcadas:
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
using Unity.MLAgents;
using Unity.MLAgents.Sensors;
public class MLPaddle : Agent
{
public float _speed = 1;
public GameObject _ball;
private Rigidbody2D _rb;
private Rigidbody2D _rbball;
////////////////////////////////
////////ML AGENTS METHODS///////
////////////////////////////////
/// <summary>
///
/// </summary>
public override void Initialize()
{
Debug.Log("Initialize");
_rb = this.GetComponent<Rigidbody2D>();
//just in case we forgot to add the ball in the editor
if (_ball == null) _ball = GameObject.FindGameObjectWithTag("Ball");
_rbball = _ball.GetComponent<Rigidbody2D>();
}
/// <summary>
///
/// </summary>
public override void OnEpisodeBegin()
{
}
/// <summary>
/// Just one action and two values: go up or down
/// </summary>
/// <param name="vectorAction"></param>
public override void OnActionReceived(float[] vectorAction)
{
Debug.Log("OnActionReceived");
float lUp = vectorAction[0];
lUp -= 1;
if ((transform.position.y < GameManager._gm._downWall.transform.position.y +
transform.localScale.y / 2 && lUp < 0))
{
AddReward(-0.05f);
return;
}
if ((lUp > 0) && (transform.position.y > GameManager._gm._topWall.transform.position.y -
transform.localScale.y / 2))
{
AddReward(-0.05f);
return;
}
if (lUp != 0)
{
_rb.MovePosition(transform.position +
transform.up * lUp * _speed * Time.deltaTime);
AddReward(-0.0005f);
}
}
/// <summary>
/// Collect the observations.
/// -Vector2d: ball.position.
/// -Vector2d: paddle.position.
/// </summary>
/// <param name="sensor"></param>
public override void CollectObservations(VectorSensor sensor)
{
Debug.Log("ColectObservations");
sensor.AddObservation(_ball.transform.localPosition.x);
sensor.AddObservation(_ball.transform.localPosition.y);
sensor.AddObservation(_rbball.velocity.x);
sensor.AddObservation(_rbball.velocity.y);
sensor.AddObservation(transform.localPosition.y);
//Total observations 5 positions.
}
/// <summary>
/// Control the agent with the cursors.
/// </summary>
/// <param name="actionsOut"></param>
public override void Heuristic(float[] actionsOut)
{
float lUp = 1f;
if (Input.GetKey(KeyCode.UpArrow))
{
lUp = 2f;
}
if (Input.GetKey(KeyCode.DownArrow))
{
lUp = 0f;
}
// Put the actions into an array and return
actionsOut[0] = lUp;
}
////////////////////////////////
////////COMMOM METHODS//////////
////////////////////////////////
private void OnTriggerEnter2D(Collider2D collision)
{
if (collision.tag == "Ball")
{
collision.GetComponent<Ball>().changeXDirection();
//ADDReward to our agent
AddReward(2f);
}
if (collision.tag == "Wall")
{
//ADDReward to our agent
AddReward(-0.05f);
}
}
}
Los resultados del aprendizaje.
Contamos con dos curvas de aprendizaje totalmente diferentes, y la única diferencia entre ellas es el fichero .yaml. Vamos a ver primero las curvas y después estudiaremos las diferencias de los ficheros para intentar averiguar él porque de la gran diferencia en nuestras curvas.
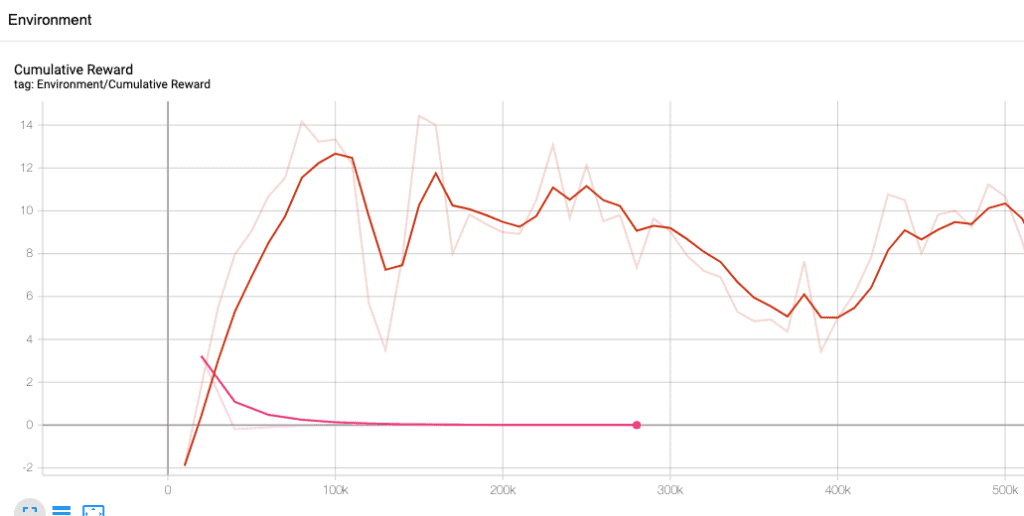
Tenia la intención de llegar a los 500000 pasos en los dos aprendizajes, pero…. no hizo falta, la curva Rosa tenia un problema claro que tenia que estudiarse. Ninguna de las dos curvas es idónea, la Rosa salta a la vista, no consigue aprender nada. La roja no acaba de encontrar su estado correcto, por lo que parece que tiene problemas en llegar al punto optimo de aprendizaje. Pero esta claro que la roja es mucho mejor… y solo hay una diferencia entre las dos curvas: el fichero trainer_config.yaml. Comparten todos los otros datos, desde la configuración del agente en Unity hasta el valor de premios, en realidad es el mismo script, no se realizó ningún cambio.
Veamos primero el fichero .yaml usado en la curva roja (la buena):
behaviors:
mlpong:
trainer_type: ppo
hyperparameters:
batch_size: 32
buffer_size: 1280
learning_rate: 0.0003
beta: 0.001
epsilon: 0.2
lambd: 0.99
num_epoch: 8
learning_rate_schedule: linear
network_settings:
normalize: true
hidden_units: 64
num_layers: 2
vis_encode_type: simple
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0
keep_checkpoints: 5
max_steps: 10000000
time_horizon: 1000
summary_freq: 10000
threaded: true
Veamos el fichero de la curva rosa que no ha aprendido nada, con las lineas con diferencias resaltadas…. y intentaremos explicar qué significan.
behaviors:
mlpong:
trainer_type: ppo
hyperparameters:
batch_size: 32
buffer_size: 256
learning_rate: 0.0003
beta: 0.005
epsilon: 0.2
lambd: 0.95
num_epoch: 3
learning_rate_schedule: linear
network_settings:
normalize: false
hidden_units: 256
num_layers: 1
vis_encode_type: simple
reward_signals:
extrinsic:
gamma: 0.9
strength: 1.0
keep_checkpoints: 5
max_steps: 500000
time_horizon: 5
summary_freq: 20000
threaded: true
Lo primero que tengo que decir, es que es una magnitud de cambios nada recomendable para un solo paso. Es decir, cuando se trata ajustar el rendimiento del modelo de aprendizaje con el fichero trainer_config.yaml, hacer tal cantidad de cambios no es una buena practica. En mi defensa tengo que decir, que el primer fichero lo utilice en uno de los ejemplos del curso de introducción al Machine Learning y funciono correctamente, mientras que el segundo lo he bajado de los ejemplos, basado también en un Space Type discrete, que se pueden encontrar en el GIT de ml-agents de UNITY, llamado GridWorld.
Venga…. vamos a ello, estudiemos las diferencias:
- hyperparameters:
- buffer_size. Pasamos de 1280 a 256. El rango de este parámetro para ppo suele estar entre 2048 y 409600 (sinceramente, se podrían haber quedado en 400000, alguna razón matemática se me escapa). Indica cuántas experiencias son necesarias para modificar el modelo. Este parámetro tiene otra limitación, tiene que ser un múltiplo de veces superior al batch_size. En ambos casos se cumple. Pero en el caso del fichero que no aprende (linea rosa), es un valor muy pequeño, por debajo de la recomendación. ¿Nos preguntamos porque? Seguramente la respuesta la encontremos en la definición del entorno, por lo que parece no utiliza variables de observación. Si nos encontramos con una linea inestable de aprendizaje, podemos considerar en subir el valor y acercarnos a la parte superior de la recomendación.
- beta. Pasamos de 0.001 a 0.005. Indicamos la aleatoriedad de la politica al inicio del entreno. Los dos valores se encuentran en el rango inferior de lo recomendado, que esta entre 0.001 y 100. Como más alto sea el valor mas acciones “random” tomara el agente al inicio del aprendizaje. Durante el proceso del aprendizaje el valor va tendiendo a 0, ya que el sistema cada vez tiene mas información para tomar decisiones que no sean aleatoria. Como podéis entender, en nuestro sistema, en el que solo hay dos decisiones a tomar (subir o bajar), este valor no es muy importante, y podemos mantenerlo cerca de 0.
- lambd. Ha pasado de 0.99 a 0.95. El agente puede estar en diferentes estados antes de conseguir un objetivo, y cada uno de estos estados tiene un valor asociado, mas alto, como más cerca del objetivo le sitúa. El valor de estos estados se va modificando cada vez que se recalcula el modelo. Pues bien, lambd, indica cuánto tiene que fiarse el sistema del valor de cada uno de estos estados, o si tiene que confiar más en los rewards que esta obteniendo en el paso actual. Como más bajo sea el valor, más confiará en el pasado. La verdad es que no considero que la diferencia de este parámetro en los dos ficheros haya tenido demasiada importancia en el funcionamiento del agente.
- num_epoch. Pasamos de 8 a 3. El rango recomendado va de 3 a 8. Como mas grande sea el valor, mas estable el aprendizaje, como más bajo más rápido. Este valor puede explicar y mucho la inconsistencia de la curva roja, así como su rápido aprendizaje.
- network_settings:
- normalize. Su valor puede ser True o False. Indica si se debe aplicar la normalización al vector de observaciones. Puede beneficiar en sistemas complejos que usen el State continuous, pero es contraproducente en sistemas simples que usen un state discrete. Por lo que en nuestro primer fichero, el de la linea roja podríamos cambiarlo a False.
- num_layers. Ha cambiado de 2 a 1. El valor recomendado esta entre 1 y 3. Indica el número de capas escondidas en la red neuronal. Se pueden ir aumentando a medida que el problema es más complejo. Cómo nuestro escenario es muy simple podríamos pasar con 1 sola capa.
- hidden_units. Pasamos de 64 a 256. El rango recomendado esta entre 32 y 512. Representa el número de unidades que tiene cada una de las capas escondidas. Suelen estar ligadas al numero de acciones a realizar, como mas acciones o más complejas, más alto. Nuestro problema es sencillo. Posiblemente se podría pasar con 32.
- max_steps. Indica el número máximo de pasos que da el agente, o agentes, antes de finalizar el proceso de aprendizaje. Un paso es todo un ciclo completo de observación->acción->observación. Se suele tener un rango entre 500.000 y 10 millones de pasos.
- time_horizon. Cuántos pasos tiene que dar un agente antes de que estos se incorporen a la experiencia del sistema. Se puede reducir en el caso de que un agente reciba muchos premios o castigos para que estos pasen cuanto antes al motor de Machine Learnig. Hemos pasado de 1000 a 5. Esta claro que la diferencia es abismal, y que por lo simple del sistema y los pocos premios o castigos que recibe tendríamos que reducir mucho el número del primer fichero. Los valores suelen estar entre 32 y 2048.
- summary_freq. Ojala todos fueran tan sencillos como este. Indicamos cada cuanto queremos que se actualicen los datos en TensorBoard. Por defecto el valor es 5000, yo suelo subirlo…. no tiene ninguna afectación en cuanto al modelo.
Bueno, ya hemos visto las diferencias, pero hay valores muy importantes que no se han modificado. Vamos a explicarlos, los que están dentro del apartado de Hyperparameters, y intento explicar cómo afectan a un modelo como el usado de ejemplo.
- hyperparameters:
- learning_rate: Como más alto sea el learning, rate mas se van actualizando los pesos de la red neuronal…. entonces ¿Qué narices pongo yo aquí? ehhhh experto! Bueno, pues pues la recomendación es ponerlo muy bajo, ya que si se actualiza mucho el modelo puede perder información de los entrenos a medida que pasa el tiempo. Es mejor que tenga un update pequeño pero continuo en el tiempo. Por lo que si vemos que nuestro aprendizaje no es estable y el reward no sube de una forma continua, podríamos reducirlo aún más. Resumiendo, si lo subimos el aprendizaje puede ser mas rápido pero mas inestable. En nuestro ejemplo, podríamos reducirlo a 0.0001.
- learning_rate_schedule: podemos escoger constant, o linear. Este segundo va bajando de forma constante hasta llegar a 0. Es decir, qué va decrementando muy poco a poco el valor que ya hemos informado en learning_rate. En caso de que tengamos un entorno que varia mucho, y que puede tener diferencias en cada paso que da el agente es mejor escoger constant. En cambio, si este entorno no varia, podemos escoger linear, ya que nos ira bien que la red neuronal se vaya actualizando menos cada vez, ya que al tener pocos cambios que aprender cada vez puede apoyarse más en lo aprendido anteriormente. Pero atención, esto solo es verdad si nuestro trainer_type es ppo…. que lo va a ser casi siempre, realmente superior al anterior sac. (Esta última frase no hace falta entenderla del todo).
- batch_size: Entendamos que hace un agente: Primero observa el entorno, después decide o hace una acción y finalmente observa el entorno otra vez y espera nuestros premios o castigos. Este tamaño indica cuántos pasos se pueden guardar para producir un update de nuestra red neuronal. Cada modificación (Update) consiste en: alimentar la red neuronal con las observaciones, calcular los errores cometidos basandose en los premios o castigos y ajustar el peso de las variables teniendo en cuenta la participación que se les presupone en los errores cometidos. Es decir… una búsqueda de nodos culpables. Este valor tiene que ser muy diferente si estamos trabajando en un space continuous o discrete. Para un espacio continuous el rango es de 512 a 5120, mientras que si el espacio es discrete el rango estaría situado entre 32 y 512. Como en nuestro ejemplo, la línea roja aprende, pero es muy inestable, se podría incrementar el batch_size hasta acercarnos, o incluso llegar, al límite máximo. Pero como ya sabemos, una mayor estabilidad suele comportar un aprendizaje mas lento.
- epsilon. Con un rango típico de 0.1 a 0.3. Es quizás uno de los más complicados de entender. Indica el porcentaje que puede cambiar la politica en cada update. El valor va decrementando en el tiempo hasta 0.1 (que significa un 10%). En casi todos los sitios se recomienda un valor de 0.2. Supongo que la gente se ha puesto deacuerdo en que si no acabas de tener claro como afecta… pues nos quedamos en el medio del rango recomendado. Como siempre, si vemos que nuestra curva de aprendizaje tiene curvas inexplicables, podemos tratar de reducir el valor, pero…. hay otros parámetros que tocar antes.
Creando un fichero .yaml para nuestro PONG con ML-Agents.
Tenemos la información suficiente! Hemos visto dos curvas con dos ficheros totalmente, con resultados dispares, y tenemos conocimiento de cómo afecta cada uno de los parámetros de nuestro fichero trainer_config.yaml. Por lo que podemos crear uno que sea capaz de mejorar el proceso de aprendizaje!
Veamos cómo queda el fichero nuevo y después ya explicamos cada uno de los cambios y su porque.
behaviors:
mlpong:
trainer_type: ppo
hyperparameters:
batch_size: 64 #32
buffer_size: 512 #256000 #256
learning_rate: 0.0003
beta: 0.005
epsilon: 0.2
lambd: 0.90 #0.80 #0.95
num_epoch: 3 #3
learning_rate_schedule: linear
network_settings:
normalize: true #false
hidden_units: 256
num_layers: 2
vis_encode_type: simple
reward_signals:
extrinsic:
gamma: 0.9
strength: 1.0
keep_checkpoints: 5
max_steps: 1000000
time_horizon: 1000
summary_freq: 5000
threaded: true
¿Qué diferencias tenemos con el fichero que no ha aprendido nada?
- batch_size: de 32 a 64. Nos encontramos que la primera prueba nuestra linea de aprendizaje era muy inestable. Subo el batch_size para que no haya tantas variaciones entre los pasos, aunque el aprendizaje sea mas lento.
- buffer_size: de 256 a 512. Primero se ha realizado una prueba aumentado considerablemente su valor a 256000. El resultado a estado un fracaso, con un agente que se quedaba paralizado. Se reduce el valor a 512, intentando conseguir una curva con menos picos, al irse incorporando los resultados al modelo más despacio.
- lambd: de 0.95 a 0.90. Como los rewards se dan tan solo cuando la pala golpea la pelota, y puede suceder en pocas ocasiones al principio intentamos, reduciendo el valor de lambd, que se tengan mas en cuenta los premios y castigos del pasado que los actuales.
- normalize: de false a true. Se dice que para sistemas simples con discrete es mejor utilizar la normalización en las observaciones… nuestro sistema es discrete, pues no hay discusión.
- num_layers: de 1 a 2. Nuestro escenario es simple, pero necesita contar con la historia de premios anteriores. La modificación de este valor no ha afectado demasiado a la curva.
- time_horizon: de 1 a 1000. Esta ha sido la modificación más importante!!!!! Solo tocando este parámetro ya pasamos de una curva que no aprende nada a una que consigue aprender. Las otras variaciones han dado estabilidad al proceso de aprendizaje, pero esta es la que le ha permitido tener una linea ascendente. Le estamos indicando que incoporé los datos al sistema al tener como mínimo 1000 pasos.
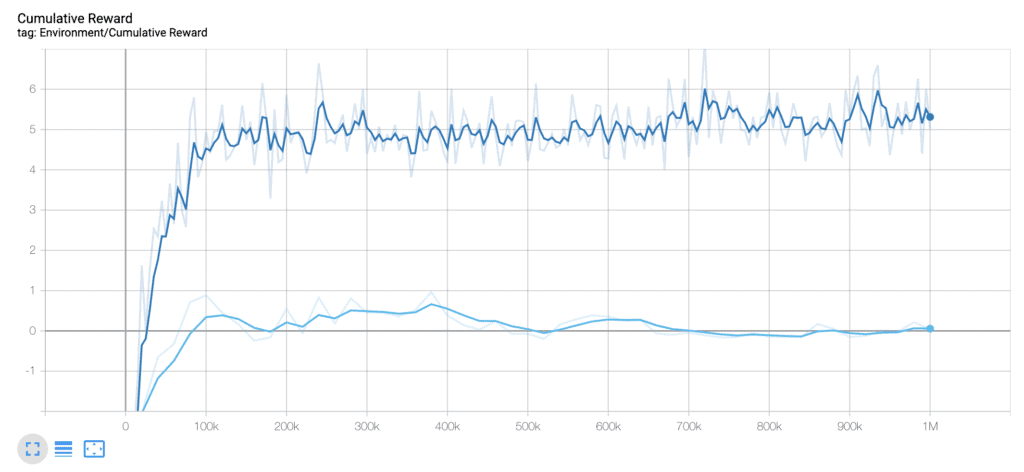
Aquí vemos las dos curvas…. el cambio se ha producido cambiando tan solo tocando las seis variables que hemos explicado del fichero .yaml. Es decir pasamos de un sistema incapaz de aprender a otro que crea un agente totalmente funcional, capaz de ser un rival importante de cualquier jugador que se quiera afrontar a él.
Creo que ha quedado clarísimo que el fichero .yaml es muy importante.
La importancia de la observación empírica en el proceso de aprendizaje.
me ha quedado una frase preciosa, para decir: tienes que estar mirando mientras se aprende…. vale, no tienes que estas las tres horas delante de la pantalla… pero si que tienes que pasarte unos cinco minutos cada hora y observar el comportamiento del agente que estamos entrenado. Por que dos agentes, con una misma curva, o una curva muy parecida a simple vista, y con unos resultados casi calcados, pueden tener un comportamiento muy diferente entre ellos.
Veamos un ejemplo:
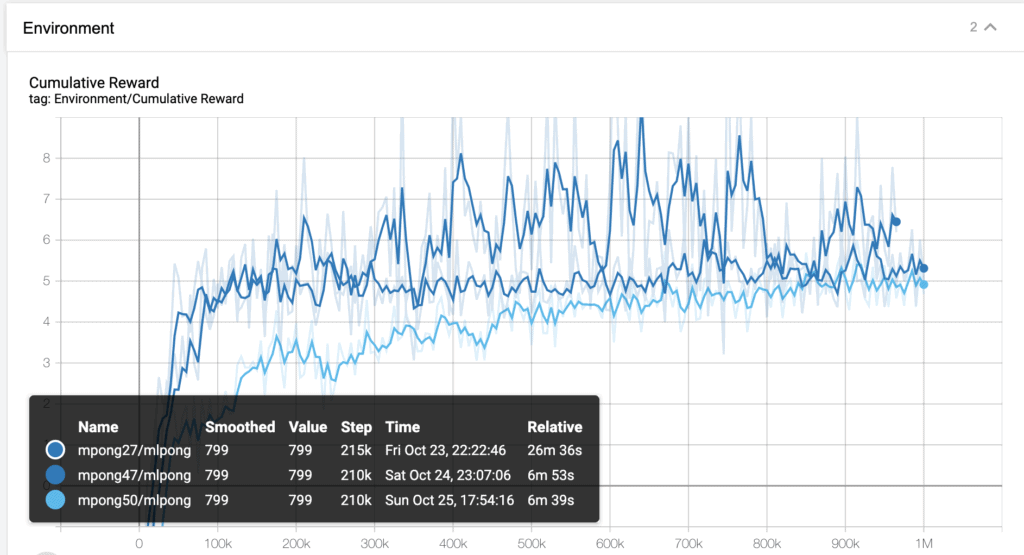
Lo primero que tengo lamentar, es que tensorboard me ha pintado de azul las tres curvas y es complicado diferenciarlas. Pero tenemos la leyenda, y ahora vamos a ligar estas curvas con tres vídeos del comportamiento de nuestra pala. Ya veréis como aunque la curva es parecida y parece que llegan al mismo lugar (sobretodo las dos inferiores) el comportamiento del agente es diferente.
Vemos el funcionamientos correspondiente a la curva mpong27. La que esta en la parte superior. Si miramos la curva nos podría parecer la mejor solución, pero cuando vemos al agente, podemos observar cómo su movimiento, aunque efectivo, es poco elegante y no parece un jugador humano…. la pala no deja de moverse en ningún momento.
El resultado producido por la curva mpong47 es mucho mejor, si nos referimos a la elegancia. La pala se mueve mucho mas como si fuera un jugador humano el que la esta moviendo, y no pierde efectividad.
al observar la curva mpong50 vemos un movimiento, quizás demasiado seco, aunque podría pasar por el de un jugador preciso y experto. Lo que hay que destacar es cómo dos curvas, que en un principio pueden ser tan parecidas como la 47 y la 50, dan como resultado agentes que se puede observar a simple vista sus diferencias de funcionamiento.
Las tres curvas dan como resultados agentes que devuelven la bola en la máyoria de casos, pero, uno de ellos yo no lo incorporaría a ningún juego, ya que tiene un estilo demasiado errático!
Estas diferencias se han producido tan solo modificando el fichero de configuración .yaml. En los tres casos estamos hablando de mismo script, mismo peso de castigo y mismo peso de premios, con las mismas observaciones… solo hemos cambiado la configuración.
Creo que lo podemos dejar aquí, que cada uno saque sus conclusiones, pero la mía es que vale mucho la pena, por no decir qué es imprescindible, dedicar horas a obtener un buen fichero .yaml de configuración para nuestro sistema de MLAgents.