Curso avanzado de ML-Agents de UNITY.
Creamos un NPC capaz de perseguir un target en un entorno Variable. Primera parte.
Queremos crear un NPC que sea capaz de acudir a diferentes misiones, o lugares. En particular, vamos a tener a un personaje humanoide que perseguirá monolitos.
Cualquier duda o comentario de la lección no dudeis en dejarla en el foro del curso.
Los monolitos son estructuras que se iluminan, y el personaje debe acudir a la que está iluminada. Este comportamiento nos podría servir para un NPC con pequeñas misiones. Como los típicos realizar acciones sencillas y comunes como: ves a comer, ves a dormir, ves a jugar. En este caso nosotros hemos puesto monolitos, pero podrían ser habitaciones diferentes, o objetos para recoger.
La parte más importante es que queremos que nuestro NPC sea capaz de funcionar correctamente aunque cambiemos el escenario. Es decir, no siempre vamos a tener dos muros, y no siempre van a estar en la misma situación. También queremos que los targets vayan variando su posición y que el agente sea capaz de encontrarlos.
Pero lo mejor es que lo veamos:
El Script de nuestro ML-Agent.
Como ya sabéis el agente tiene que tener un script, que sera el responsable de, entre otras, las siguientes acciones:
- Recolectar las observaciones y enviarlas al motor de Machine Learning.
- Ejecutar las acciones que recibe del mismo motor.
- Implementar la función Heuristica que permite controlar el agente sin necesidad de tener el motor de machine learningdando ordenes
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
using UnityEngine.UI;
using Unity.MLAgents;
using Unity.MLAgents.Sensors;
using Unity.MLAgents.Actuators;
public class AgentImitation2 : Agent
{
[Header("Speed")]
[Range(0f, 5f)]
public float _speed = 2f;
[Header("Turn speed")]
[Range(50f, 300f)]
public float _turnSpeed = 50f;
public bool _training = true;
protected Rigidbody _rb;
[SerializeField]
protected Target[] _target;
protected Animator _anim;
protected Vector3 _previous;
public Text _contadorText = null;
public float _puntos = 0;
float[] _oldstateTargets = new float[3];
public override void Initialize()
{
_rb = GetComponent<Rigidbody>();
_anim = GetComponent<Animator>();
_previous = transform.position;
//MaxStep part Agent class
if (!_training) MaxStep = 0;
}
public override void OnEpisodeBegin()
{
_rb.velocity = Vector3.zero;
_rb.angularVelocity = Vector3.zero;
NewPosition();
_previous = transform.position;
}
public override void OnActionReceived(ActionBuffers actions)
{
float lForward = actions.DiscreteActions[0];
float lTurn = 0;
if (actions.DiscreteActions[1] == 1)
{
lTurn = -1;
}
else if (actions.DiscreteActions[1] == 2)
{
lTurn = 1;
}
_rb.MovePosition(transform.position +
transform.forward * lForward * _speed * Time.deltaTime);
transform.Rotate(transform.up * lTurn * _turnSpeed * Time.deltaTime);
AddReward(-1f / MaxStep);
}
public virtual void Update()
{
float velocity = ((transform.position - _previous).magnitude) / Time.deltaTime;
_previous = transform.position;
_anim.SetFloat("multiplicador", velocity);
}
public override void CollectObservations(VectorSensor sensor1)
{
float[] stateTargets = new float[_target.Length];
for (int n = 0; n < _target.Length; n++)
{
stateTargets[n] = 0f;
if (_target[n].isLigthActive()) stateTargets[n] = 1f;
//Distance to the target.
//1 position * n.
sensor1.AddObservation(Vector3.Distance(_target[n].transform.position, transform.position));
//Direction to the target
// 3 position * n
sensor1.AddObservation((_target[n].transform.position - transform.position).normalized);
}
if (stateTargets[0] == 1 && _oldstateTargets[0] != 1)
Debug.Log("Red");
if (stateTargets[1] == 1 && _oldstateTargets[1] != 1)
Debug.Log("Yellow");
if (stateTargets[2] == 1 && _oldstateTargets[2] != 1)
Debug.Log("Blue");
_oldstateTargets = stateTargets;
//3 positions state of the lights.
sensor1.AddObservation(stateTargets);
//Vector 3 positions.
sensor1.AddObservation(
transform.forward);
//18 observations if n = 3
}
public override void Heuristic(in ActionBuffers actionsOut)
{
var discreteActionsOut = actionsOut.DiscreteActions;
discreteActionsOut.Clear();
int lForward = 0;
int lTurn = 0;
if (Input.GetKey(KeyCode.UpArrow))
{
lForward = 1;
}
if (Input.GetKey(KeyCode.LeftArrow))
{
lTurn = 1;
}
else if (Input.GetKey(KeyCode.RightArrow))
{
lTurn = 2;
}
discreteActionsOut[0] = lForward;
discreteActionsOut[1] = lTurn;
}
private void OnTriggerStay(Collider other)
{
if (true)
{
if (other.CompareTag("target"))
{
if (other.GetComponent<Target>().isLigthActive())
{
GiveReward(1.5f);
}
else
{
GiveReward(-0.5f);
}
}
if (other.CompareTag("borders"))
{
GiveReward(-0.05f);
}
}
}
protected void GiveReward(float premio)
{
if (_training)
{
AddReward(premio);
}
if (_contadorText != null)
{
_puntos += premio;
_contadorText.text = _puntos.ToString();
}
}
protected void NewPosition()
{
bool possiblePosition = false;
int intentos = 100;
Vector3 potentialPosition = Vector3.zero;
while (!possiblePosition || intentos >= 0)
{
intentos--;
potentialPosition = new Vector3(
transform.parent.position.x + UnityEngine.Random.Range(-3f, 3f),
0.555f,
transform.parent.position.z + UnityEngine.Random.Range(-3f, 3f));
//If we have colliders in the array we have a collision
Collider[] colliders = Physics.OverlapSphere(potentialPosition, 0.5f);
if (colliders.Length == 0)
{
transform.position = potentialPosition;
possiblePosition = true;
}
}
}
}
Vamos a ver en detalle las funciones más importantes del script.
CollectObservations.
public override void CollectObservations(VectorSensor sensor1)
{
float[] stateTargets = new float[_target.Length];
for (int n = 0; n < _target.Length; n++)
{
stateTargets[n] = 0f;
if (_target[n].isLigthActive()) stateTargets[n] = 1f;
//Distance to the target.
//1 position * n.
sensor1.AddObservation(Vector3.Distance(_target[n].transform.position, transform.position));
//Direction to the target
// 3 position * n
sensor1.AddObservation((_target[n].transform.position - transform.position).normalized);
}
if (stateTargets[0] == 1 && _oldstateTargets[0] != 1)
Debug.Log("Red");
if (stateTargets[1] == 1 && _oldstateTargets[1] != 1)
Debug.Log("Yellow");
if (stateTargets[2] == 1 && _oldstateTargets[2] != 1)
Debug.Log("Blue");
_oldstateTargets = stateTargets;
//3 positions state of the lights.
sensor1.AddObservation(stateTargets);
//Vector 3 positions.
sensor1.AddObservation(
transform.forward);
//18 observations if n = 3
}
Primero se tiene que explicar que hay una decisión de diseño, como mínimo, discutible. Si queremos que el personaje persiga al target iluminado lo más óptimo sería pasar como observación tan solo los datos del target iluminado y obviar los otros. Pero, he decidido intentar un enfoque totalmente diferente, para ver cómo funciona el motor relacionando valores que en un principio para el no tienen ninguna relación.
Vigilamos los tres targets y al mismo tiempo tenemos una array que contiene tres floats, cada uno representa a un target, y el de los targets apagados contiene un 0, mientras que el del target iluminado contiene un 1. Pero el motor de machine learning no sabe esta relación, tiene que construirla a medida que va aprendido.
Repito: EL DISEÑO DE ESTA FUNCIÓN NO ES EL MÁS ÓPTIMO PARA SOLUCIONAR ESTE PROBLEMA.
Las observaciones que informamos son:
- El array de floats que nos indica que target esta activo.
- Distancia del personaje a cada uno de los targets.
- Dirección desde el personaje a cada uno de los targets.
- El transform.forward del personaje.
Aparte de estas observaciones el personaje cuenta con un componente RayPerceptionSensor3D, preparado para identificar los componentes con las etiquetas: untagged (es decir sin etiqueta), target y borders.

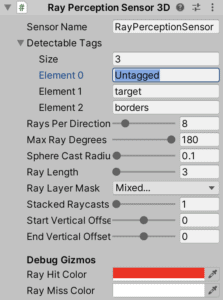
Los datos que recolecta el Ray Percetion Sensor 3D se pasan directamente al motor Anaconda, por lo que es una forma muy sencilla de recolectar un gran número de datos.
OnActionReceived.
public override void OnActionReceived(ActionBuffers actions)
{
float lForward = actions.DiscreteActions[0];
float lTurn = 0;
if (actions.DiscreteActions[1] == 1)
{
lTurn = -1;
}
else if (actions.DiscreteActions[1] == 2)
{
lTurn = 1;
}
_rb.MovePosition(transform.position +
transform.forward * lForward * _speed * Time.deltaTime);
transform.Rotate(transform.up * lTurn * _turnSpeed * Time.deltaTime);
AddReward(-1f / MaxStep);
}
Recibimos el vector de acciones, que le hemos dado forma en la configuración del IDE.
La primera posición del array le indica al personaje si debe andar o no. Es tan fácil como usarlo de multiplicador en la función MovePosition del RigidBody del personaje, con lo que si nos llega un 0 el personaje no va a moverse.
El segundo valor del array nos indica si debemos continuar rectos, o girar a la izquierda o derecha.
El fichero .yaml original.
Ahora vamos a ver cómo es el fichero original con el que hemos realizado el primer aprendizaje. Para crearlo hemos partido de un fichero que viene con los ejemplos de UNITY, llamado 3dballhard. Podéis encontrar información sobre los proyectos de ejemplo que ofrece Unity en su página de github.
Si necesitáis más información sobre el fichero de configuración .yaml la tenéis en el este mismo curso en la lección: la importancia del fichero.yaml.
behaviors:
3DBallHard:
trainer_type: ppo
hyperparameters:
batch_size: 120
buffer_size: 12000
learning_rate: 0.0003
beta: 0.001
epsilon: 0.2
lambd: 0.95
num_epoch: 3
learning_rate_schedule: linear
network_settings:
normalize: true
hidden_units: 128
num_layers: 2
vis_encode_type: simple
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0
keep_checkpoints: 5
max_steps: 500000
time_horizon: 1000
summary_freq: 12000
threaded: true
Quizás no sea el mejor de los proyectos en los que me podría basar. Es un proyecto más simple, se trata de un agente que tiene que sujetar una bola en su cabeza.
 Seguro que este proyecto usando ML-Agents de ejemplo que nos da UNITY os suena.
Seguro que este proyecto usando ML-Agents de ejemplo que nos da UNITY os suena.
Hacemos unas modificaciones previas al fichero .yaml modificando las siguientes variuables:
- buffer_size: 12000 -> 37200
- num_epoch: 3 -> 8
- batch_size: 120 -> 3000
Todas estas modificaciones van buscando una mayor estabilidad en el proceso de aprendizaje, aunque esto conlleve un inicio de aprendizaje mas lento. Ahora ya estamos listos para realizar los primeros aprendizajes, vamos a ver.
Empieza el proceso de aprendizaje.
Todos los procesos se han realizado teniendo 12 agentes funcionando paralelamente en un macbook pro 13′ del 2020 con 16 gb de RAM y un Intel i5 a 2.0GHz. Com veis no es una máquina excesivamente potente y no cuenta con una gráfica dedicada. Esto significa dos cosas, la primera es que los procesos de aprendizaje no va a ser muy rápidos y la segunda, es que el requisito de maquina que piden los ml-agents para sacar buenos resultados no son muy elevados. Es verdad que como mejor capacidad de proceso menos va a tardar el aprendizaje, pero la máquina no es una barrera de entrada infranqueable.

Test5.
Si vale, hay cuatro ejecuciones previas, que me han servido para averiguar que tenia un error en el script, por lo que los descarto, pero habré dedicado unas 8 horas a realizar los procesos de aprendizaje y darme cuenta de que tenia que haber un error mas allá de una mala configuración.
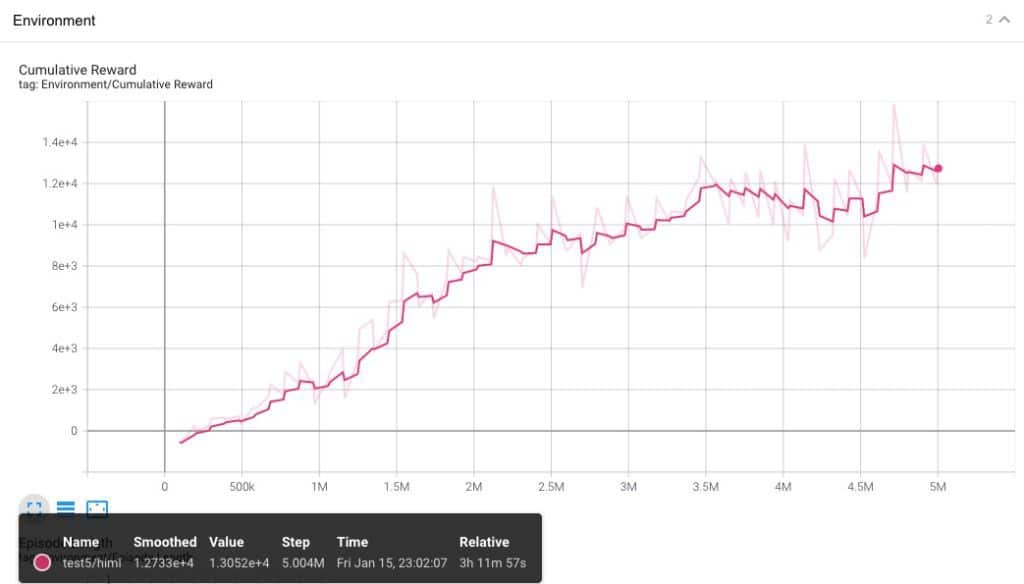
Vale, el aprendizaje no fue mal del todo, se ha conseguido una curva que sube, pero el aprendizaje esta lleno de baches. Hemos realizado 5 millones de pasos en 3 horas y pico y nuestro agente no es capaz de alcanzar los targets de una forma estable. Vamos a realizar algunas modificaciones en el siguiente proceso de aprendizaje.
Test 6.
Vamos a modificar los MaxSteep de cinco millones a 20, y dejare el proceso de aprendizaje durante una noche entera. Es importante aprovechar estas horas para realizar los procesos de aprendizaje. Aunque la modificación más importante es que decido eliminar el código de los targets que hace que se cambien de posición. Van a estar siempre en el mismo sitio.
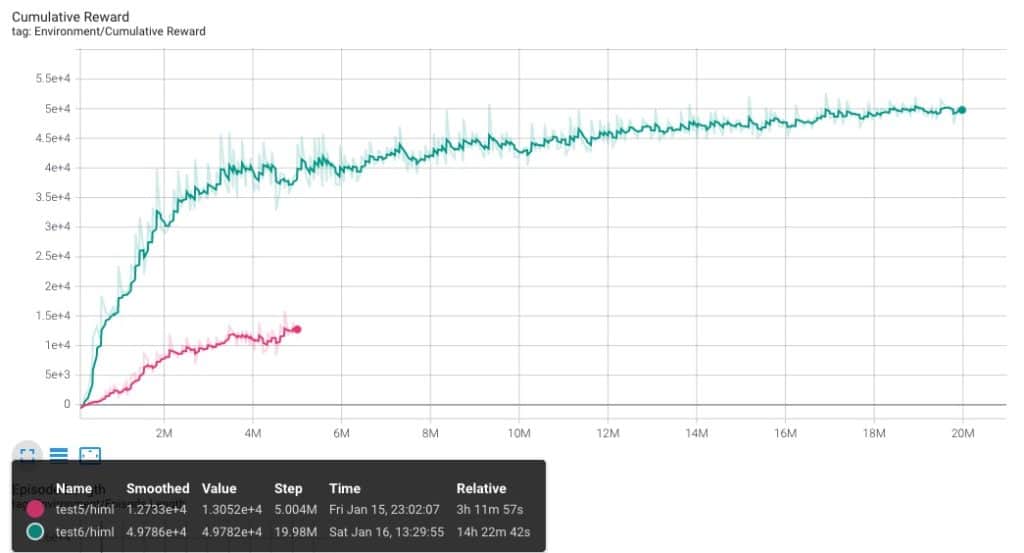
Casi 20 Millones de pasos y 14 horas y media de aprendizaje! El único cambio introducido ha sido reducir la dificultad del experimento, ya que ahora los targets no se mueven. Esto ha significado una curva con mucha más ganancia, y que a pesar de estar ejecutandose durante bastante tiempo todavía no ha alcanzado el tope de aprendizaje. Recordemos que una curva llega al máximo cuando ya no hay crecimiento, es decir, se convierte en una linea plana.
Se mantiene el problema de variación. Fijaros en las lines de color un poco mas claras que acompañan a cada una de las lineas de aprendizaje. Esas nos marcan los picos sin tener el cuenta el suavizado del visualizador. Es decir, son más reales. Pero el resultado a sido bastante bueno, el personaje se comporta de forma más que correcta, por lo que decido guardar el modelo generado como un cerebro a utilizar en UNITY.
Guardar el modelo como un cerebro en UNITY es tan sencillo como arrastrar el fichero .onnx que encontramos en las carpets results hacia la ventana Project de UNITY. Entonces ya podremos informar el campo Model del agente con el fichero y este podrá funcionar de forma autónoma.
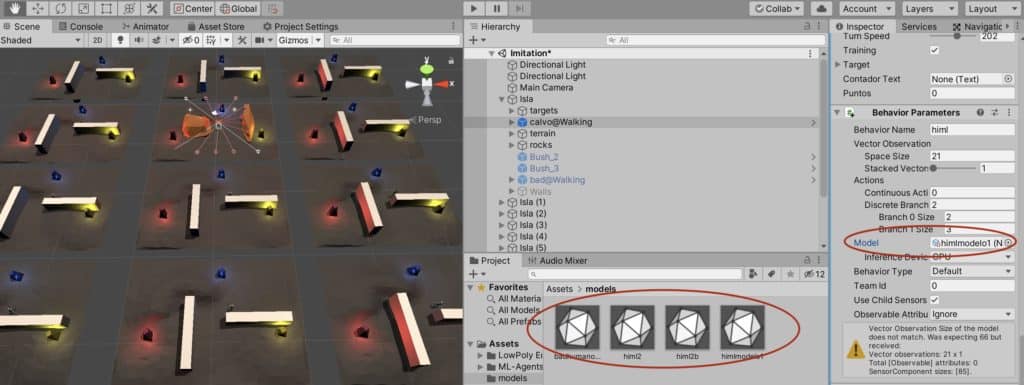
Vamos a ver cómo reacciona el agente funcionando de forma autónoma, y le vamos a introducir una roca nueva, a ver si es capaz de esquivarla.
Primera ejecución del test 6.
La roca del medio es nueva, no estaba cuando nuestro ml-agent se entrenaba. Vemos que el agente encuentra bastante bien los monolitos y que el camino que usa para ir de uno a otro es bastante bueno. Pero en el segundo 00:09 del vídeo se queda empujando a la roca. Lo que me hace pensar que no controla del todo bien los nuevo obstáculos. Una posible causa es que las rocas no están etiquetadas, y ademas, si os fijáis el el 00:10 podemos ver cómo pasa por encima de una de las rocas, por lo que quizás no las puede identificar como elementos que tiene que esquivar estén donde estén.
Así que decido hacer una segunda ejecución del test 6, pero esta vez cambiando de posición la roca del medio para que séa más complicado esquivarla.
Segunda ejecución del test 6.
Se queda atascado en el segundo 0:05, pero contra una roca que ya existía en el escenario del entreno. Al cabo de unos segundos consigue encontrar la ruta al monolito amarillo. No se le ve que tenga problemas encontrando el camino, quizás con un entreno mejor podría encontrar rutas más óptimas. Me doy por satisfecho, y decido hacer una tercera ejecución, esta vez voy a activar la parte del código que cambia de sitio a los monolitos unos segundos después de que el personaje llegue a ellos.
Veamos que sucede.
Tercera ejecución de Test 6.
A partir del 00:27 ya no tenemos ningún monolito en su sitio, y el agente va realmente perdido. Incluso antes, cuando ha cambiado tan solo un monolito de sitio parece que le cuesta más encontrar al resto. Posiblemente le cambie una referencia que para él era fija, es decir, al mover aunque sea solo un monolito y tener como referencia su posición, aunque no sea el monolito encendido, despista a nuestro ml-agent. Cuando todos los monolitos han cambiado de sitio el ml-agent va perdidisimo, parece que recuerda donde estaban originalmente, cosa que es totalmente lógico. Posiblemente lo que ha aprendido el ml-agent es que tiene que ir a una posición fija, no donde este el monolito, ya que estos no cambiaban de posición durante el proceso de aprendizaje.
La conclusión más importante que sacamos es la que ya he comentado al principio! El diseño de la función CollectObervations es ineficiente. No tan solo para que le cueste más empezar el aprendizaje, sino por que incluso despista, le estamos dando unos datos que no le sirven ni como referencia. Pero, como mínimo hemos demostrado que el ml-Agent puede encontrar la relación entre las dos variables.
Vamos a hacer unos intentos más, decido cambiar las rocas por unos muros y ponerles etiquetas. Quiero que el Ml-Agent identifique claramente los muros como obstáculos insalvables.
test 7.
Repetimos el proceso de aprendizaje, sin cambiar nada más que las rocas por muros, y el resultado es el mismo, pero veamos cómo han ido las ejecuciones.
Primera ejecución test7.
Ninguna sorpresa, si prendio con las rocas tenía que aprender con los muros y así ha sido.
Segunda ejecución test7.
Hacemos una modificación muy sencilla, cambiamos el tiempo que están los monolitos iluminados y pasamos de 20 a 8. Es posible que no lo hayáis visto porque los videos están acelerados a x8, pero el monolito dura 20 segundos iluminado.
Al ml-agent no le afecta para nada que los monolitos cambien más rápidamente.Encuentra el camino correcto sin problemas.
Vamos a introducir un muro nuevo, a ver cómo se comporta el agente.
Tercera ejecución de test7.
No esta mal! Esquiva correctamente el muro, se da contra él un par de veces, pero nada bloqueante. Parece que el agente está preparado para que se le altere un poco el escenario.
Hagamos una última prueba, volvemos a activar el cambio de posición de los monolitos y quitamos el muro.
Cuarta ejecución test 7.
Las tres primeras veces encuentra perfectamente al monolito, están en su posición inicial. En el 00:15 ya vemos que pasa algo, se queda enfrente de monolito rojo (que ha cambiado de posición), pero no llega a tocarlo. A partir de aqui se pierde, cuando se ilumina el monolito amarillo va a buscarlo, pero a su posición original, y el monolito no está allí. El agente ha aprendido a ir a la posición del monolito, no a ir al monolito. El agente está muy perdido, como si todas sus referencias ya no existieran….
Pero quedan dos opciones:
- Realizar el entreno con los monolitos moviendos.
- Arreglar de una vez la función CollectObservations y dejarnos de experimentos.
Test 9.
Entrenamos al ml-agent con los monolitos cambiando de posición.
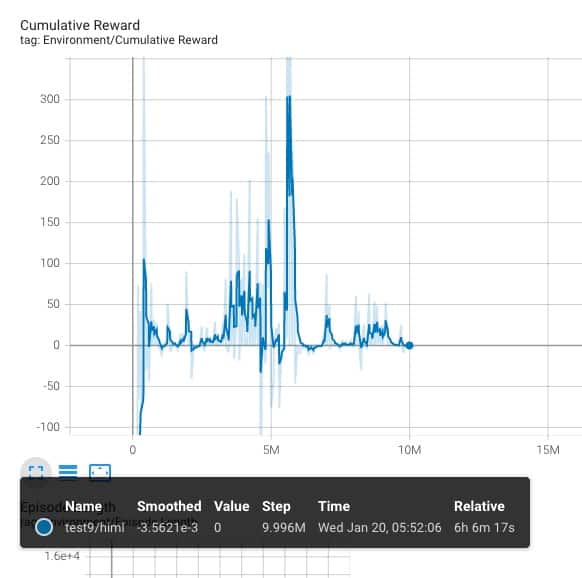
Bueno, pues ya vemos, que no lo ha conseguido. La curva parte de muy abajo, pero, nunca llega a tener una tendencia clara, va avanzando a trompicones… algo esta mal, muy mal. Quizás todo el fichero .yaml, o quizas la función CollectObservation, o quizas tendriamos que usar una aproximación diferente al proceso de aprendizaje, usando tecnicas como el imitation learning o el curriculum learning… pero NO.
Hay un paso antes del aprendizaje que es el de diseño, y este modelo está mal diseñado! Lo podemos arreglar, seguramente, modificando el fichero .yaml, dandole de entrada ejecuciones de ejemplo correctas, o cualquier otra técnica, pero todo esto solo enmascararía el problema: TENEMOS QUE MODIFICAR LA FUNCION CollectObservations.
Lo vemos en la segunda parte.